
Am 2. März 2021 hielt Jürgen Schmidt, der Geschäftsführer von STRG, eine Keynote auf dem JETZT-Summit, einer jährlich stattfindenden Konferenz für Digital Marketing Professionals in Österreich und der DACH-Region. Aufgrund der Pandemie wurde die Konferenz komplett online abgehalten, doch die virtuellen Teilnehmer waren nicht weniger beeindruckt von Schmidts Präsentation, wie man ihren begeisterten Chat-Kommentaren entnehmen kann.
Schmidts natürliches Talent, komplexe Ideen auf unterhaltsame, leicht verständliche Weise zu vermitteln, kam voll zur Geltung. Sein Vortrag mit dem Titel „Data-Diven Publishing Reloaded – The Matrix is Real“ behandelte viele der heißesten Themen der MarTech-Branche – natürliche Sprachverarbeitung, maschinelles Lernen, semantische Inhaltsanalyse, Verhaltensökonomie, Verbesserung der Datenqualität und einige andere.
Ein zentrales Thema seines Vortrags war, wie man die Irrationalität der menschlichen Intelligenz mit der Rationalität der künstlichen Intelligenz in Einklang bringen kann. Anhand von unterhaltsamen Beispielen, die belegen, wie dies zu schlechten, unbeabsichtigten Ergebnissen führen kann (z. B. konnte ein Berliner Künstler Google Maps einen Stau vortäuschen, als er mit 100 Android-Telefonen eine Straße entlanglief), kritisierte Schmidt künstliche Intelligenz, die auf einem „überwachten“ Lernmodell basiert (d. h., wenn sie im Voraus von Menschen instruiert wird).
Schmidt erläuterte, wie der massive Anstieg der Rechenleistung und die ausgefeilte Programmierung heutzutage ein alternatives, „unüberwachtes“ Modell des maschinellen Lernens bieten, bei dem Computer Daten analysieren und klassifizieren können, ohne dass ihnen im Vorfeld restriktive Regeln vorgegeben werden. Ein solches Modell erfordert jedoch riesige Datenmengen, was für große englischsprachige Märkte wie die USA von Vorteil ist, während es in Europa und Asien nur begrenzt möglich ist.
Ein drittes Modell, das „verstärkende“ bzw. Reinforcement Learning, ähnelt dem uralten „Zuckerbrot und Peitsche“ Prinzip, das Lernen durch Belohnung und Bestrafung darstellt. Schmidt sagt, dass die Figur des Agenten Smith aus den Matrix-Filmen ein Beispiel dafür ist, wie eine solche verstärkungsbasierte virtuelle Maschine in der Lage ist, selbstständig Strategien zu entwickeln, mit wenig oder gar keinen vorherigen Anweisungen, indem sie einfach aus ihrem eigenen Verhalten lernt.
“Ein Reinforcement-Learning-Modell benötigt keine riesige Datenmenge, da selbst eine kleine Datenmenge innerhalb eines einzigen Portals mittels Datensimulation extrapoliert werden kann.”
Laut Schmidt benötigt ein Reinforcement-Learning-Modell nicht den riesigen Datensatz, den ein unüberwachtes Modell benötigt, da selbst eine kleine Menge an User-Journey-Daten innerhalb eines einzelnen Portals mithilfe von Datensimulationsalgorithmen extrapoliert werden kann, welche selbstständig durch Versuch und Fehlverhalten lernen. Dies kann zu intelligenteren Analysen führen, da die falsche Rückkopplungsschleife vermieden wird, die bei unzureichenden Daten entstehen kann – zum Beispiel, wenn Portale schlechte Klickraten-Daten verwenden, um „ansprechende“ Inhalte zu fördern, die wiederum häufiger angeklickt werden, unabhängig von ihrem tatsächlichen Interesse für den Nutzer.
In einem Interview vor seiner JETZT-Keynote, sagte Schmidt für die Internet World Austria: „Wenn man die realen Ergebnisse, die mit den heute verfügbaren Daten erzielt werden, wie z.B. die Klickraten, mit älteren Methoden vergleicht, kann man nicht wirklich viel Verbesserung sehen, weil sich niemand die Mühe macht, die grundlegende Qualität der Daten zu berücksichtigen – ihre inhaltliche Genauigkeit.“ Er fügte hinzu: “Nur weil jemand irgendwo auf einen Link geklickt hat, sagt die traditionelle Tracking-Analyse [den Content-Publishern] nur, dass sie sich auf die gleichen verwandten Themen konzentrieren sollen.”
Schmidt bemängelte, dass “wir im Bereich der Marketingtechnologie dazu neigen, anderen Branchen hinterherzulaufen, insbesondere wenn man sie mit modernen Technologien wie fahrerlosen Autos, Bilderkennung und Deepfake-Videos vergleicht.” Es ist daher faszinierend, Entwicklungen in anderen Bereichen zu studieren und zu lernen, wie man sie auf die Marketingtechnologie anwenden kann. So kam die STRG auf die Idee, die Datensimulation zu nutzen – indem wir uns ansahen, welche experimentellen Methoden Tesla und die Robotik verwenden.”
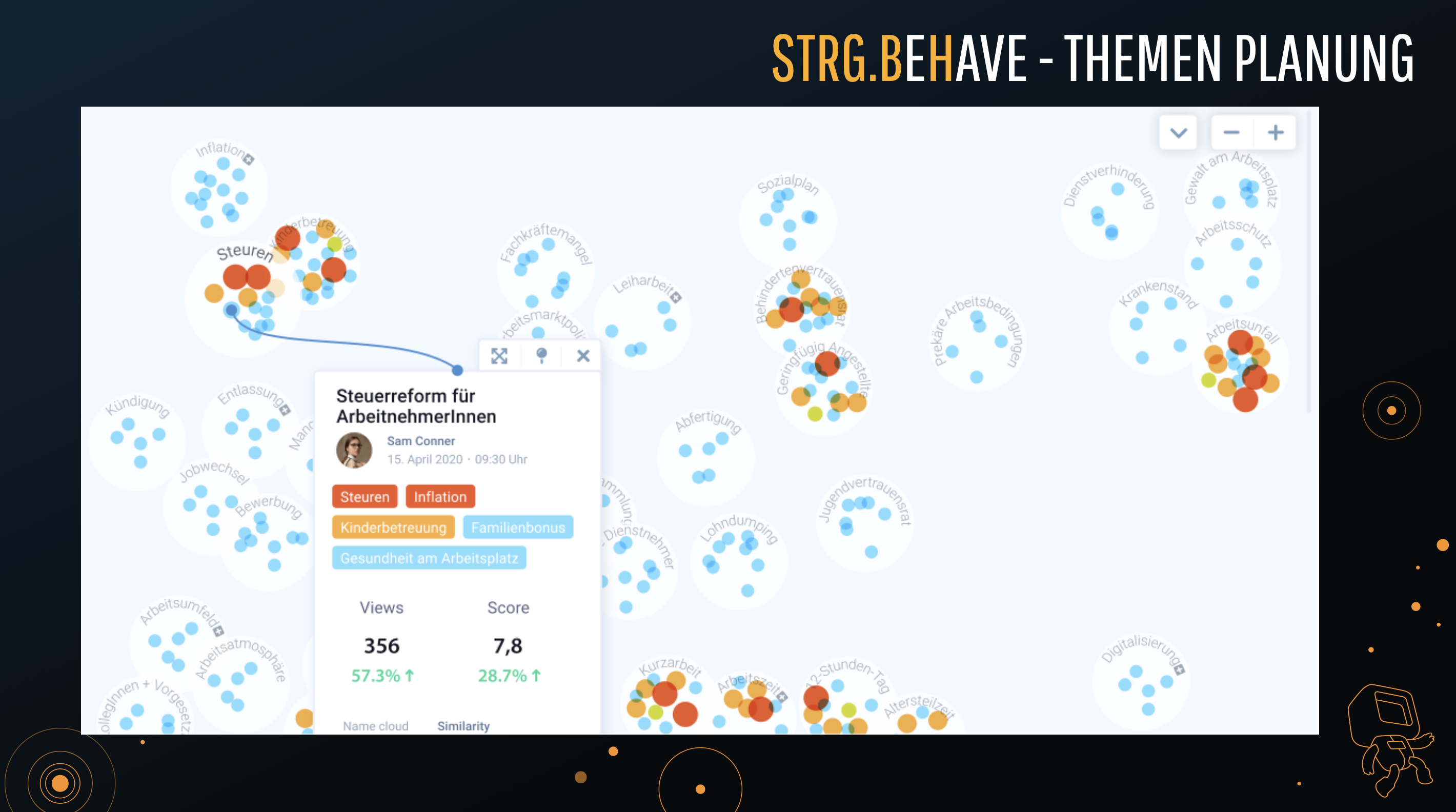
Der Einsatz von künstlicher Intelligenz für digitale Medien eröffnet viele Möglichkeiten, mit denen sich Portale verbessern lassen – vor allem im Bereich E-Commerce und Digital Publishing. STRG entwickelt Content-Management-Systeme, die eine proprietäre STRG.BeHave KI-Technologie nutzen, um die Analysen auf völlig neuartige Weise zu analysieren, z. B. unter Verwendung von Prinzipien der Verhaltensökonomie.
“Die Möglichkeiten der Datensimulation eröffnen völlig neue Anwendungsmöglichkeiten. Bei geringem Verkehrsaufkommen ist die Analyse von Tracking-Daten nicht sehr hilfreich.”
Im Gespräch mit der IWA sagte Schmidt: “Wir erforschen derzeit die Vorteile, die sich durch den Einsatz von Datensimulationen ergeben.” Beim datengesteuerten Publizieren kommt es auf die Datenqualität an, die selten diskutiert wird. Selbst KI kann aus schlechten Daten keine guten Lösungen machen. “Garbage in, garbage out” wird immer die Regel sein. “Die Möglichkeiten der Datensimulation eröffnen völlig neue Anwendungen. Bei geringem Verkehrsaufkommen ist die Analyse von Tracking-Daten nicht sehr hilfreich. KI braucht eine gewisse Menge und Breite an Daten, um zuverlässig zu sein.”
Außerdem stellt Schmidt fest, dass der Datenschutz in Europa sehr ernst genommen wird, und er hält dies für richtig. Das regulatorische Umfeld führt zu neuen Innovationen, welche die digitalen Industrien über die heutigen fragwürdigen Zustimmungs-/Opt-out-Maßnahmen der Nutzer weit hinausbringen werden. Es wird immer wahrscheinlicher, dass Cookies von Drittanbietern bald durch Technologien wie Federated Learning of Cohorts (FLoCs) ersetzt werden, bei denen individuelle Nutzerdaten durch Datensätze von Nutzergruppen zum Zwecke der gezielten Ausrichtung von Werbung und Inhalten ersetzt werden. Google erforscht derzeit ein „Privacy Sandbox“-Konzept zur Abschaffung von Cookies von Drittanbietern, und die STRG steht an der Spitze dieser Bewegung zur Vereinfachung der Marketingtechnologie bei gleichzeitigem Schutz der Privatsphäre des Einzelnen. Schmidt ist der Meinung, dass in der ‚cookielosen‘ Zukunft viel mehr hochwertige Daten zur Verfügung stehen werden, wovon auch kleinere Portale profitieren werden.
Um mehr über die Technologie zu erfahren, die wir zur Verbesserung des digitalen Publizierens einsetzen, kontaktieren Sie entweder Jürgen Schmidt oder Michael Dosser.
- Call STRG's CEO Jürgen, or write a mail juergen.schmidt@strg.at Mobile: +43 699 1 7777 165





